
目录
1. 概览
1.1. 总体介绍
周志华教授曾表达过这样的思想:快速入门一个学科,不是把一个学科,一本书里面的一个章节研究的非常透彻,而是快速通读全书,大致了解整本书在讲些什么,然后在后续的学习中持续发掘其中的细节,直至慢慢掌握其精髓。以我的理解,就是快速写出它的“hello world”,大概就能一定程度上体会到它在讲些什么。
而手写数字识别,作为神经网络的入门课,就扮演着“hello world”这样的角色。
1.2. 名词解释
为后续理解作基本的铺垫
CNN,全称卷积神经网络(Convolutional Neural Network),是一种深度学习的算法,特别适合于处理图像数据。CNN在图像识别、语音识别等许多领域都有广泛的应用。
CNN的主要特点是它可以自动地学习到从原始数据中提取哪些特征是重要的,这是通过训练过程中的权重调整实现的。这与传统的机器学习方法不同,传统的机器学习方法通常需要人工选择和提取特征。
CNN的基本组成部分包括卷积层、池化层(Pooling Layer)和全连接层(Fully Connected Layer)。卷积层用于从输入数据中提取局部特征,池化层用于降低数据的维度,全连接层则用于将学习到的特征进行最终的分类或回归。
MNIST(Modified National Institute of Standards and Technology database)是一个广泛用于训练各种图像处理系统的大型手写数字数据库。它包含60,000个训练样本和10,000个测试样本,每个样本都是一个28x28像素的灰度图像,代表了0到9的一个数字。
MNIST数据集是由美国国家标准与技术研究院(NIST)的原始数据集修改和混合而来的。它的目标是作为一个简单的计算机视觉基准数据集,用于科研人员测试和比较不同的机器学习和图像处理算法。
MNIST数据集的一个重要特点是,它的样本已经进行了预处理,包括中心化、归一化等,这使得它非常适合用于基础的机器学习和深度学习实验。因此,MNIST数据集经常被用作教学和研究的基准数据集,特别是在图像识别和机器学习的初级教学中。
Ground Truth 是一个术语,通常在机器学习和计算机视觉领域中使用,指的是数据的真实标签或真实值。在监督学习中,我们通常有一组带有标签的训练数据,这些标签就是 “ground truth”。这些真实的标签用于训练模型,使模型能够学习到输入数据和输出标签之间的映射关系。
例如,在图像分类任务中,每张图片的 “ground truth” 就是图片的真实类别;在物体检测任务中,每个物体的 “ground truth” 是物体的类别和其在图像中的位置(通常表示为一个边界框);在回归任务中,每个输入的 “ground truth” 是一个连续的数值。
“Ground truth” 是评估模型性能的基础。通过将模型的预测结果与 “ground truth” 进行比较,我们可以计算出各种性能指标,如准确率、召回率、F1分数、均方误差等,以了解模型的性能如何。
threshold,在神经网络和其他机器学习模型中,”threshold” 是一个常见的术语,用来描述一个决定性的界限。当某个值超过这个界限时,模型的行为或输出会发生改变。
CUDA(Compute Unified Device Architecture)是由NVIDIA公司开发的一种并行计算平台和应用程序接口(API)。它允许开发者使用NVIDIA的图形处理单元(GPU)进行通用计算。
在过去,GPU主要用于渲染计算机图形,但由于其强大的并行处理能力,现在已经被广泛用于其他计算密集型任务,如科学计算、机器学习和深度学习等。
CUDA提供了一种相对简单的方式来编写并行代码,使得开发者可以更容易地利用GPU的计算能力。在深度学习中,使用CUDA可以显著加速训练和推理过程,特别是对于需要大量计算的任务,如训练复杂的神经网络模型。
值得注意的是,虽然CUDA是NVIDIA开发的,但许多深度学习框架(如TensorFlow和PyTorch)都支持使用CUDA,这使得它们可以在NVIDIA的GPU上运行。
cuDNN,全称CUDA Deep Neural Network library,是由NVIDIA开发的一个深度神经网络GPU加速库。它是专门为深度神经网络的前向和反向传播过程提供优化的库,包括卷积、池化、归一化、激活层等常见的神经网络操作。
cuDNN的主要优点是可以在NVIDIA的CUDA-enabled GPUs上提供高效的计算性能。它提供了低级的API,可以直接进行底层的操作,也提供了高级的API,可以方便地进行常见的操作。
许多深度学习框架,如TensorFlow、PyTorch、Caffe等,都使用cuDNN来加速在GPU上的计算。使用cuDNN可以大大提高深度学习模型的训练和推理速度。
PyTorch是一个开源的机器学习库,由Facebook的人工智能研究团队开发。它提供了两个主要功能:
- 一个n维数组库,类似于NumPy,但可以在GPU上运行以进行高效的数值计算。
- 自动微分系统(用于实现神经网络),支持动态计算图,这使得它在构建和训练复杂的深度学习模型时具有很大的灵活性。
PyTorch的一个主要特点是其动态计算图系统。在许多其他深度学习库中(如TensorFlow和Theano),计算图在运行前需要被完全定义并编译。相比之下,PyTorch允许你在运行时动态地改变计算图,这使得它更易于理解和调试,也更适合处理变长的输入数据。
PyTorch还提供了一系列的工具和库,包括用于数据加载和预处理的torchvision库,用于机器学习的torchtext库,以及用于科学计算和高级优化的torch.optim库等。
PyTorch的设计理念是简洁、灵活和直观,这使得它在研究社区中非常受欢迎,同时也逐渐在工业界得到应用。
Kaggle是一个在线社区,为数据科学家和机器学习工程师提供一个平台,他们可以在这个平台上发现和分享数据集,探索和构建模型,进行数据科学和机器学习竞赛,以及发布和分享他们的工作。
Kaggle的主要特点包括:
竞赛:Kaggle最初是作为一个平台开始的,公司和研究者可以在上面发布数据科学竞赛。这些竞赛涵盖了各种问题,从图像分类到文本分析,从预测模型到推荐系统。参与者可以提交他们的解决方案,并在公共排行榜上与其他参与者竞争。许多竞赛还提供现金奖励。
数据集:Kaggle提供了一个平台,用户可以发布、搜索和下载数据集。这些数据集涵盖了各种主题,包括(但不限于)公共卫生、经济学、图像识别、自然语言处理等。
Kernels/Notebooks:Kaggle提供了一个在线代码执行环境,称为Kaggle Kernels(现在更名为Kaggle Notebooks)。用户可以在这个环境中编写Python或R代码,进行数据分析和建模,然后分享他们的代码和结果。
讨论论坛:Kaggle社区有一个活跃的讨论论坛,用户可以在这里讨论竞赛、数据集、编程问题,以及数据科学和机器学习的最新趋势。
Kaggle是一个很好的资源,无论你是一个数据科学新手,还是一个有经验的专业人士,都可以在这里学习、分享和发展你的技能。
超参数,在机器学习中,超参数是在开始学习过程之前设置的参数,而不是通过训练得到的参数。换句话说,超参数是模型训练之前由数据科学家或机器学习工程师手动设置的参数。
超参数可以影响模型的学习过程和模型的性能。例如,对于神经网络,超参数可能包括学习率(决定模型学习的速度),批次大小(每次训练步骤中用于更新模型权重的样本数量),以及训练的轮数(整个数据集通过模型的次数)等。
另一个例子是支持向量机(SVM)的惩罚参数C和核函数的参数。这些超参数控制模型的复杂性和灵活性。
选择合适的超参数是机器学习中的一个重要任务,因为不同的超参数可能会导致模型的性能有很大的差异。这个过程通常需要大量的实验和调整,也可以使用一些自动化的方法,如网格搜索、随机搜索或贝叶斯优化等。
batch,在机器学习和深度学习中,”batch”是指用于一次模型更新的数据集的子集。批处理大小(batch size)是一个超参数,定义了每次迭代(或更新)中用于计算梯度的样本数量。
例如,假设你有一个包含1000个样本的训练集,如果你设置批处理大小为100,那么你的模型将在每个训练周期(epoch)中进行10次更新,每次更新使用100个样本。
批处理的主要优点是:
计算效率:使用批处理可以利用并行处理能力,比如GPU,从而提高计算效率。
稳定的梯度估计:使用更大的批处理可以得到更稳定(但可能不是更准确)的梯度估计。
内存使用:对于大型数据集,可能无法一次性将所有数据加载到内存中,批处理可以有效地管理内存使用。
然而,选择批处理大小也是一个权衡。较小的批处理可能会导致更频繁的更新,可能会导致训练过程更快地收敛,但也可能导致梯度估计的噪声更大。另一方面,较大的批处理可能会导致更稳定的梯度估计,但可能需要更多的内存,并且可能需要更多的训练周期才能收敛。
epoch,在机器学习和深度学习中,”epoch”是指整个训练集通过模型一次的过程。换句话说,一个epoch就是模型看过训练集中的每一个样本一次。
例如,如果你有一个包含1000个样本的训练集,那么一个epoch就是模型对这1000个样本进行一次前向传播和一次反向传播。
在训练深度学习模型时,通常需要进行多个epoch,因为一次通过所有的训练数据可能不足以让模型学习到数据中的所有模式。通过多次迭代训练数据,模型可以更好地学习和适应数据。
需要注意的是,epoch的数量也是一个超参数,需要根据具体的任务和数据来设定。太少的epoch可能会导致模型欠拟合,而太多的epoch可能会导致模型过拟合。
Filter,在卷积神经网络(CNN)中,”filter”或”kernel”是一个小的矩阵,用于在图像上进行卷积运算,以检测图像中的特定特征,如边缘、线条和纹理等。
bias,在神经网络中,”bias”是一个额外的参数,它与每个神经元的输入无关,但会加入到神经元的总输入中。偏置项可以看作是神经元的阈值:只有当输入的加权总和超过这个阈值时,神经元才会被激活。偏置项可以提高模型的灵活性,使其能够更好地拟合数据。
损失函数(也被称为代价函数或误差函数)是一个用于衡量机器学习模型预测结果与真实值之间差距的函数。换句话说,它度量了模型的预测错误程度。在训练过程中,我们的目标是最小化这个损失函数。
损失函数的选择取决于你正在解决的具体问题。例如,对于回归问题(预测一个连续的输出),常见的损失函数是均方误差(Mean Squared Error,MSE),它计算的是模型预测值和真实值之间差值的平方的平均值。对于分类问题(预测一个离散的输出),常见的损失函数是交叉熵损失(Cross-Entropy Loss),它度量的是模型预测的概率分布与真实的概率分布之间的差距。
损失函数是机器学习中的一个核心概念,因为它定义了我们的优化目标。通过优化算法(如梯度下降),我们可以调整模型的参数以最小化损失函数,从而提高模型的预测性能。
反向传播(Backpropagation)是一种在神经网络中用于训练模型的关键算法。它的主要目标是通过有效地计算梯度来优化损失函数,这个梯度是损失函数相对于模型权重的偏导数。
反向传播的过程可以分为两个主要步骤:
前向传播:在这个阶段,输入数据通过网络向前传播,通过每一层的神经元和连接权重,直到生成输出。然后,这个输出与期望的输出(标签)进行比较,计算出损失函数的值。
反向传播:在这个阶段,算法从输出层开始,向后通过网络,计算损失函数相对于每个权重的偏导数(即梯度)。这个过程是通过链式法则(Chain Rule)来完成的,链式法则是微积分中的一个基本原则。
这些梯度然后被用于更新网络的权重,通常是通过一种叫做梯度下降的优化算法。这个过程在整个训练数据集上重复多次(也就是多个”epoch”),直到模型的性能达到满意的水平或者不再显著提高。
反向传播是深度学习中的一个核心算法,使得训练深度神经网络成为可能。
激活函数在神经网络中起着非常重要的作用。它们被应用于神经元的输出上,以引入非线性因素,使得神经网络能够学习并执行更复杂的任务。
如果没有激活函数,无论神经网络有多少层,它都只能表示线性变换,这大大限制了网络的表达能力。通过引入非线性激活函数,神经网络可以学习并表示更复杂的模式。
以下是一些常见的激活函数:
- Sigmoid函数:Sigmoid函数可以将任何值转换为0到1之间的值,使其可以用于输出层,以表示概率。但是,Sigmoid函数在输入值的绝对值很大时,梯度接近于0,这可能导致梯度消失问题。Sigmoid函数是一类函数而不是一个函数,意为“S型”,我们最常用的Sigmoid函数是$f(x) = \frac{1}{1 + e^{-x}}$。

- ReLU(Rectified Linear Unit)函数:ReLU函数在输入值为负时输出0,在输入值为正时输出输入值本身。ReLU函数简单且计算效率高,但是在输入值为负时,梯度为0,可能导致神经元”死亡”。

- Tanh函数:Tanh函数可以将任何值转换为-1到1之间的值,比Sigmoid函数的输出范围更广。但是,Tanh函数也存在梯度消失的问题。

- Leaky ReLU函数:为了解决ReLU函数的”死亡”神经元问题,Leaky ReLU在输入值为负时,会有一个小的正斜率。

- Softmax函数:Softmax函数可以将一组值转换为概率分布,常用于多分类问题的输出层。
选择哪种激活函数取决于具体的应用和网络结构。
2. 安装CUDA与cuDNN
虽然cpu也可以训练,但是有gpu不用白不用,效率还更高
2.1. 安装CUDA
首先确保有一个Nvidia独显,在cmd中输入
nvidia-smi

这里显示的版本是当前显卡支持的最高版本,但是我看PyTorch好像还没有适配12.4版本的CUDA,PyTorch官网支持到12.1版本,所以我们安装12.1的:

打开CUDA Toolkit Archive | NVIDIA Developer,我们下载12.1.1版本:
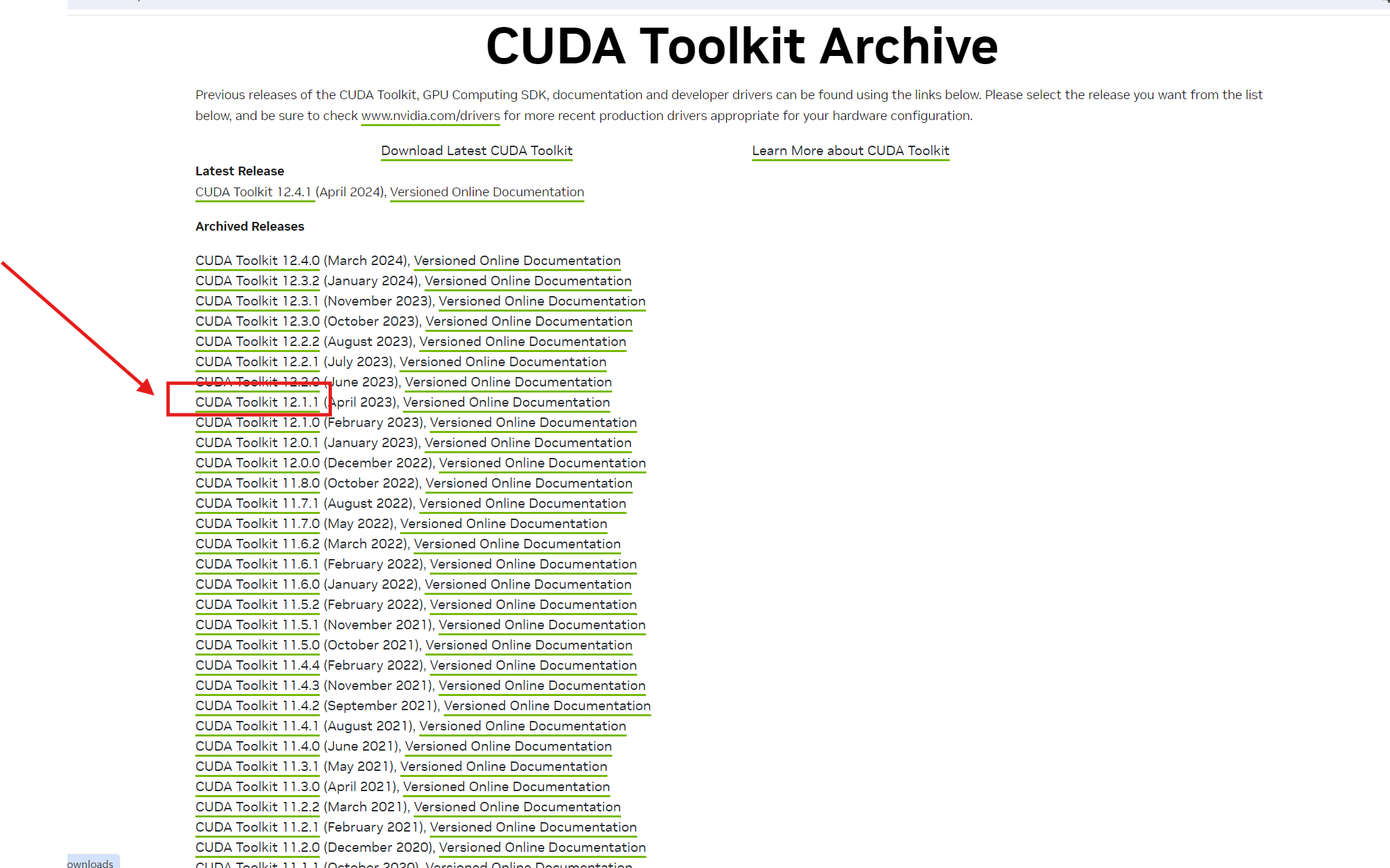

根据自己的需求下载。
然后点击自定义,一般全部安装就行:


然后打开Nvidia Experience,更新驱动到最新版

因为我之前下载过,没有这个软件的可以去下载。
安装完成之后在cmd中输入
nvcc -V

看到版本信息说明安装成功,如果没有输出这个可能是环境变量的问题:
打开系统属性:

看看系统变量里是否有这个变量:

没有就手动添加一下,正常情况下安装就会自动设置环境变量。
2.2. 安装cuDNN
安装cuDNN可以加速,新版本的cuDNN已经不需要手动配置环境变量,直接下载exe版本一步一步安装即可。

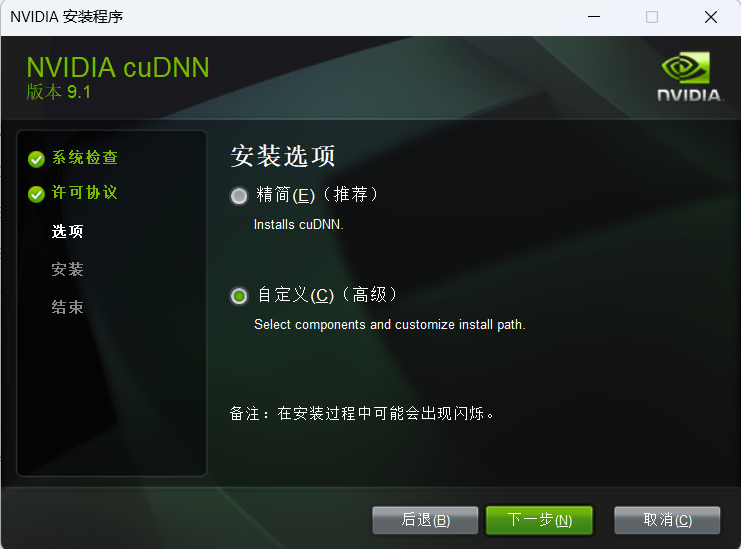

我个人喜欢全部安装,自己按需选择。
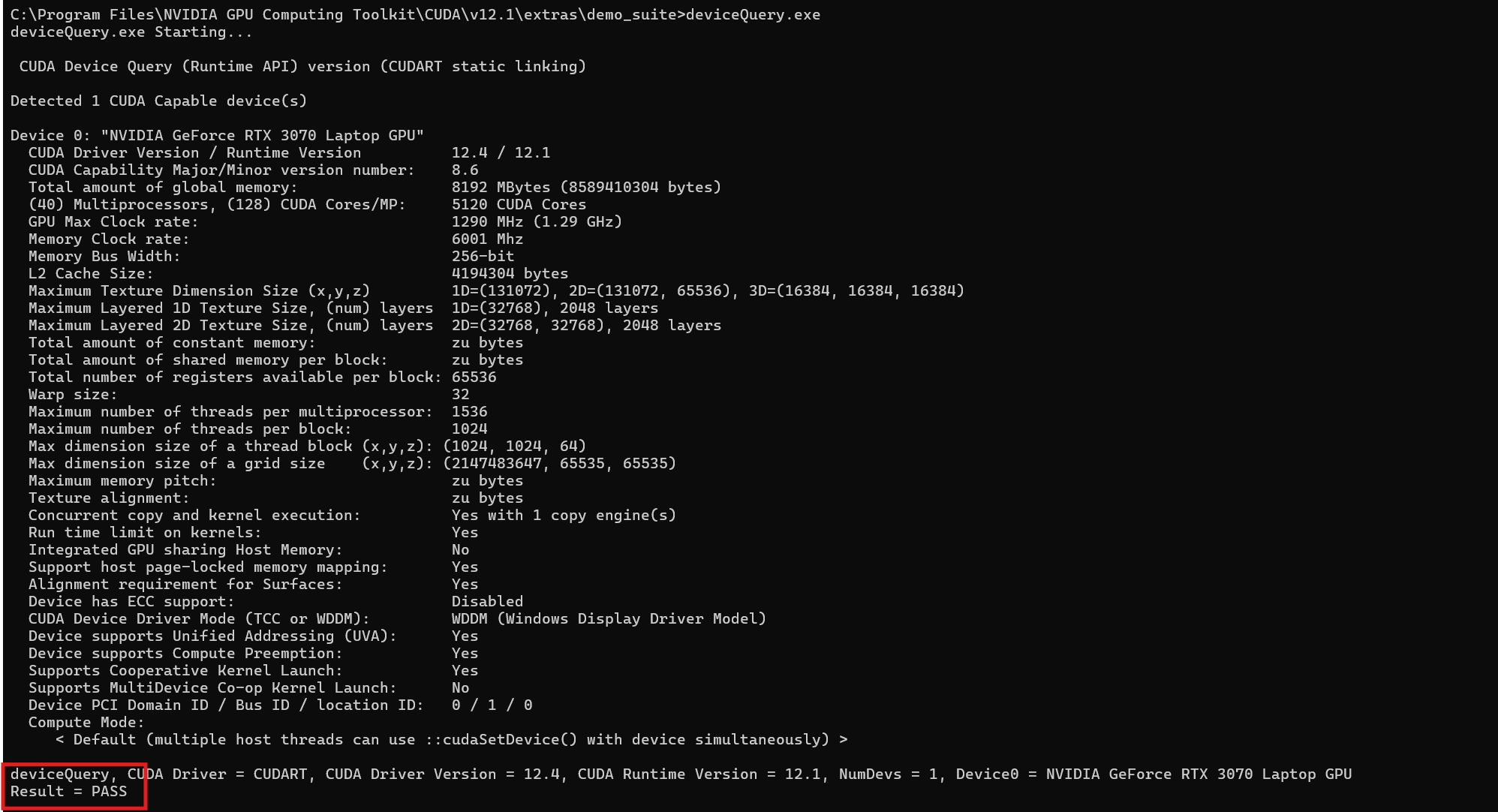
验证是否安装成功,在这个目录下执行cmd:

输入bandwidthTest.exe和deviceQuery.exe,分别看到PASS就说明安装成功:

3. 安装PyTorch CUDA版本
在PyCharm中,导入torch默认是导入cpu的版本
可以运行这段代码
import torch
print(torch.__version__)
如果版本后缀是cpu就说明安装的是cpu版本,我们需要CUDA版本的PyTorch,依据PyTorch官网的安装方式,推荐使用pip或者在Anaconda中安装,注意自己的CUDA版本:

理论上pip是最快的,但是在下载中经常出现中断,可以使用中国大陆的镜像或者使用代理安装,如果都不能安装成功也可以手动下载whl安装。
在这个页面,下载相应的版本:

前面的cu121表示CUDA12.1版本,后面的cp310表示3.10的python版本,后面表示win,amd64,选择适合自己的版本。
然后拖动到项目目录下用pip install安装。
在PyCharm中验证
import torch
if torch.cuda.is_available():
print("PyTorch can use GPUs!")
else:
print("PyTorch cannot use GPUs.")
print(torch.__version__)

然后就大功告成了。
4. 原理
4.1. 神经网络概述
本节内容引用周志华老师的课件

4.1.1. M-P神经元模型
“MP神经元”是指McCulloch-Pitts神经元,这是一种最早的、最简单的人工神经元模型。它是由Warren McCulloch和Walter Pitts在1943年提出的,因此得名。
还记得生物学中的神经元是怎么工作的吗:
- 接收信号:神经元通过其树突(一个或多个分支状的结构)接收来自其他神经元的信号。这些信号是化学物质,称为神经递质,它们从其他神经元的突触(神经元之间的连接点)释放出来。
- 整合信号:神经元的细胞体(含有细胞核的部分)将接收到的所有信号进行整合。如果这些信号的总和超过了一个特定的阈值,那么神经元就会被激活。
- 传递信号:一旦神经元被激活,就会在其轴突(从细胞体延伸出的长线状结构)上产生一个电信号,称为动作电位。动作电位会沿着轴突向下传播,直到达到轴突的末端。
- 信号传输:在轴突的末端,动作电位会导致神经递质的释放。这些神经递质会穿过突触间隙,然后与接收神经元的突触后膜上的受体结合,从而传递信号给下一个神经元。
机器学习中的神经元借鉴了生物学中的概念
对于每一个神经元,$x_i$为输入值,$w_i$是对应的权重,$\theta$是阈值(threshold),如果所有$wix_i$之和大于$\theta$,该神经元就被激活,即$f$函数(激活函数)生效。所以最终的输出为:
$$y=f(\sum\limits_{i=1}^{n} w_ix_i-\theta)$$

4.1.2. 激活函数
Activation function,也叫响应函数或者挤压函数(Squeeze function)
所谓响应也就是给一个输入值得到输出值,挤压函数指的是给一个$(-\infty, \infty)$的值,挤压到$(0,1)$之间,如下图(b)所示。
- 理想激活函数是阶跃函数,$0$表示抑制神经元而$1$表示激活神经元。
- 阶跃函数具有不连续、不光滑等不好的性质,常用的是Sigmoid函数。

特别的,对于最常见的Sigmoid函数$f(x) = \frac{1}{1 + e^{-x}}$,有这样的特性:
$$f’(x)=f(x)·(1-f(x))$$
那么$f(x)$可以理解为正的概率,$(1-f(x))$可以理解为负的概率,这对我们后面理解BP有帮助。
4.1.3. 多层前馈网络结构
如果这个多层前馈网络结构里面每一个神经元都是一个M-P神经元,我们就得到一个多层前馈神经网络
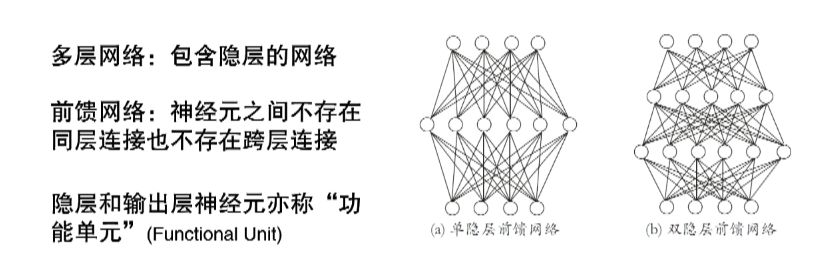
对于隐层和输出层,才有激活函数的参与,所以也被叫做功能单元。
万有逼近性(universal approximator)
多层前馈网络有强大的表示能力。
仅需一个包含足够多神经元的隐层,多层前馈神经网络就能以任意精度逼近任意复杂度的连续函数
但是,如何设置隐层神经元数是未决问题(Open Problem),实际常用”试错法“。
注意,万有逼近性并非神经网络的独有特性!
4.1.4. BP(BackPropagation:误差逆传播算法)

具体而言,在神经网络中,激活函数被应用在每一层的输出上。具体来说,每个神经元的输出是其输入与权重的线性组合,然后通过激活函数进行非线性转换。这个过程在每一层的每个神经元上都会发生。
例如,假设我们有一个三层的神经网络(输入层、隐藏层和输出层)。在隐藏层,每个神经元的输入是输入层的输出与权重的线性组合,然后这个结果通过激活函数进行非线性转换,得到隐藏层的输出。在输出层,每个神经元的输入是隐藏层的输出与权重的线性组合,然后这个结果再次通过激活函数进行非线性转换,得到最终的输出。
BP算法推导
我们把上级的输出与权重的线性组合,叫做这级的输入$\beta$,也就是输出函数$y=f(\sum\limits_{i=1}^{n} w_ix_i-\theta)$里面的$\sum\limits_{i=1}^{n} w_ix_i$,这么叫只是为了后面使公式简洁。
于是我们得到每个神经元上的预测值公式:
$$\hat{y}_j^k=f(\beta_j-\theta_j)$$
其中$k$表示第$k$个样例,$j$表示第$j$个神经元,$\theta$表示阈值(threshold),$\hat{y}$即预测值。
则整个网络在$(x_k,y_k)$上的均方误差为
$$E_k=\frac{1}{2}\sum\limits_{j=1}^{l}(\hat{y}_j^k-y_j^k)^2$$
取$\frac12$是为了求导之后消去平方,$y$是真实值(ground truth)。
所谓的训练数据就是确定一个模型中的所有参数
对于下图中的网络,输入层有$d$个神经元,隐层有$q$个,输出层有$l$个,则从输出层到隐层有$d·q$个参数,从隐层到输出层有$q·l$个参数,对于功能神经元(隐层和输出层),还有$q+l$个阈值$\theta$(threshold),加起来就是$(d+l+1)q+l$个参数,我们在训练过程中就是要确定这么多个参数。
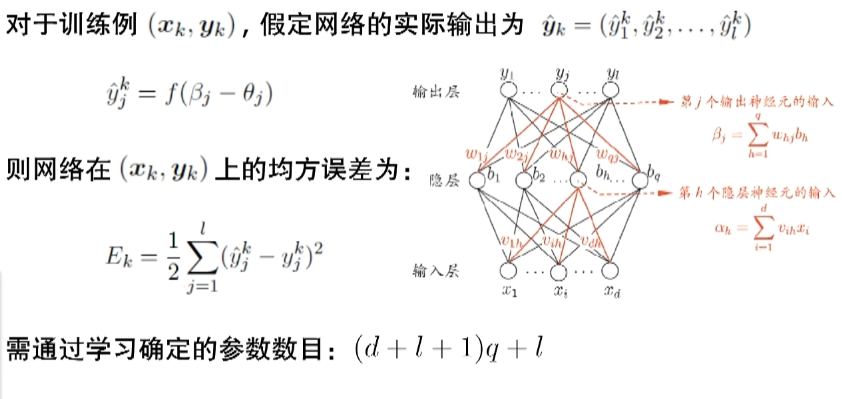
BP是一个迭代学习算法,在迭代的每一轮中采用广义感知机学习规则(多层前馈也常叫做多层感知机):
$$v\leftarrow{v}+\Delta{v}$$
其中$\Delta{v}$就是调整量,之所以要调整,就是因为有误差。
怎么调整呢?
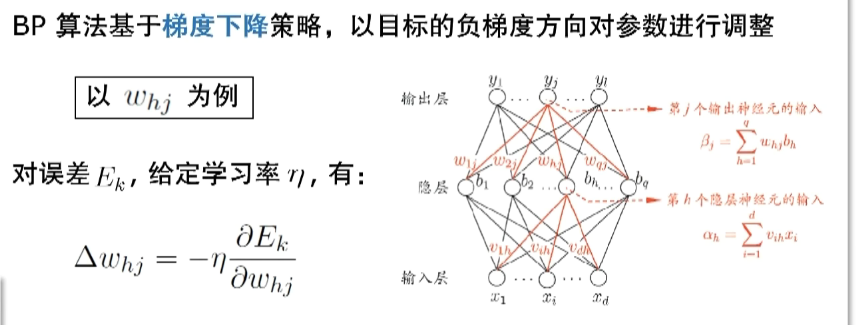
$w_{hj}$是我们要学习的一个参数(某个权重),求偏导是为了确定梯度的方向,$\eta$决定走的步长。
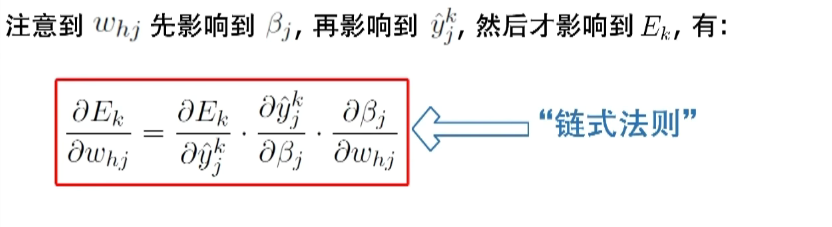

其中$b_h$就是输出层的输入值,$g_j$可以看作输出层的神经元处理。
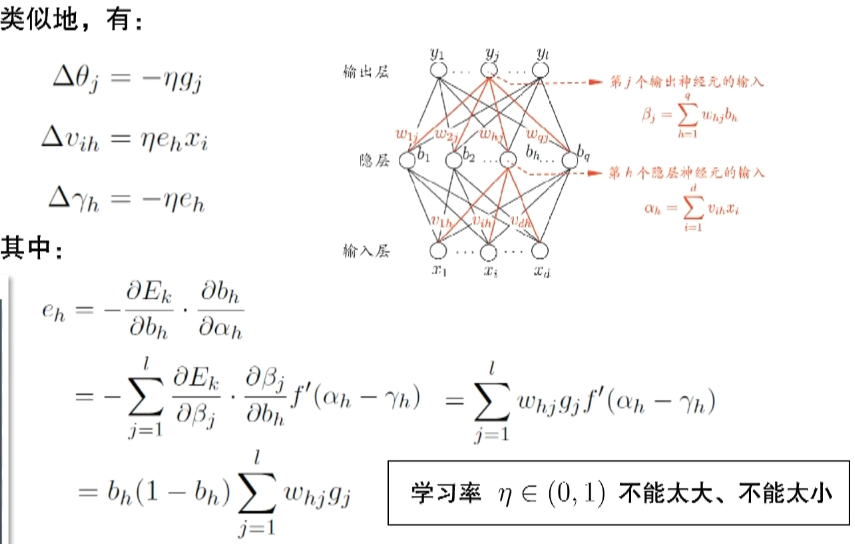
在了解各个参数是怎么调节之后,我们就知道神经网络是怎么训练的:
在输入$x$之后,整个模型会随机初始化一组参数,然后算出$\hat{y}$,然后根据$y$马上就可以算出$E$,然后根据$E$就可以得到$\Delta{w}$、$\Delta{\theta}$、$\Delta{v}$、$\Delta{\gamma}$等调整量,然后让这些值进行调整,然后不断进行这样一轮轮训练,直到$\hat{y}$收敛于$y$附近,我们的参数也随之确定下来。
震荡现象
在预测值不断逼近真实值的过程中,会发生震荡现象,比如时而大于真实值,时而小于真实值,在真实值附近震荡。
但是我们总归有办法让训练过程停止,避免一直震荡下去。比如设置训练的轮数,或者保留一组测试集,在每一轮训练完成之后拿模型在测试集和训练集上的性能做对比,如果差别很大就继续,否则小到一定程度就让它停止。
另外为了避免震荡现象比较严重,$\eta$不能太大,太小也不行,越小就意味着需要更多的训练轮数才能足够收敛。
而且$\eta$本身也可以在训练过程中灵活的调整,以加速收敛,比如训练的初期可以设置较大的$\eta$,然后慢慢减小$\eta$,以确保在收敛附近有较小的$\eta$。
4.2. 卷积原理
4.2.1. 卷积神经网络与传统神经网络的区别

简而言之,传统神经网络处理的是一维的向量,而CNN处理的是三维的。
4.2.2. 整体架构

卷积层用来提取特征,池化层用来压缩特征,全连接层用于将卷积和池化层的输出转化为最终的预测结果。
4.2.3. 何为卷积

把一张图片分割成若干个小方块,在每个小方块内进行卷积操作,用于提取这个小方块的特征。
如图中在一个$3\times3$的小方块内,每一个数字的角标表示相应的权重,这和我们在神经网络中讲的$w_i$是一个东西,我们最终的目的就是要得到一个最佳的权重矩阵。
图像颜色通道

每张彩色图片都有三个颜色通道R、G、B。
这也就是上图中的$32\times32\times3$中的$3$。对于每张图片,都要单独对每个通道进行卷积计算,然后再进行相加。
一张图片经过R、G、B三个通道分割之后,每个通道被编码成一个数字矩阵,矩阵中的每个元素用一个0-255的数字来表示颜色强度。
卷积核
每个卷积核就是一个随机初始化的权重矩阵,所谓的卷积操作就是指一个权重矩阵在图片的每个通道上作内积,如果初始输入有三个Chanel,就需要一个三维卷积核的一维分别在该通道上滑动,进行内积。当然这里面涉及到滑动的步长,比如每一次卷积核移动一格。
最终把三个通道的内积内容相加然后加上bias(偏置),就得到右边绿色的输出。我们每次可以使用多个卷积核,然后就会得到多个不同的输出,比如使用两个卷积核就使得下一次的输入数据变成$3\times3\times2$的规格。

我们知道卷积操作是为了提取特征,但是一张图片的特征往往是很小的一部分,所以我们需要进行多次卷积操作,以便高度提炼一张图片的特征值。

卷积操作中的卷积核数量会影响到下一次输入时的Channel,比如一个$5\times5\times3$的输入经过6个卷积核的卷积操作,下一次的输入Channel就变成$6$个。
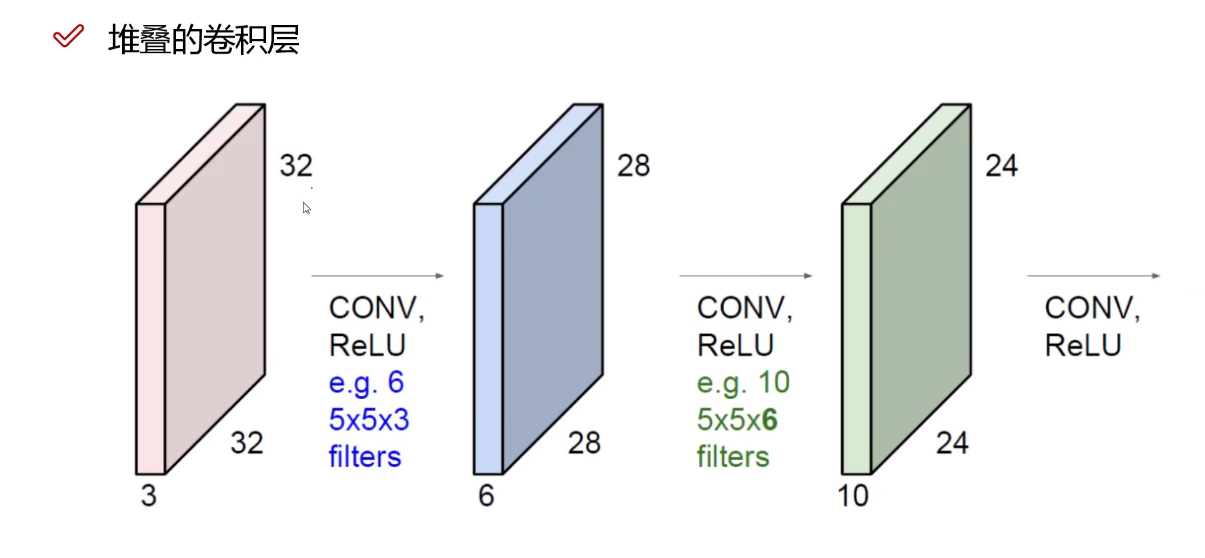
BP需要确定的参数:
步长越小,提取出来的特征图就越大,含有的特征也就越多。

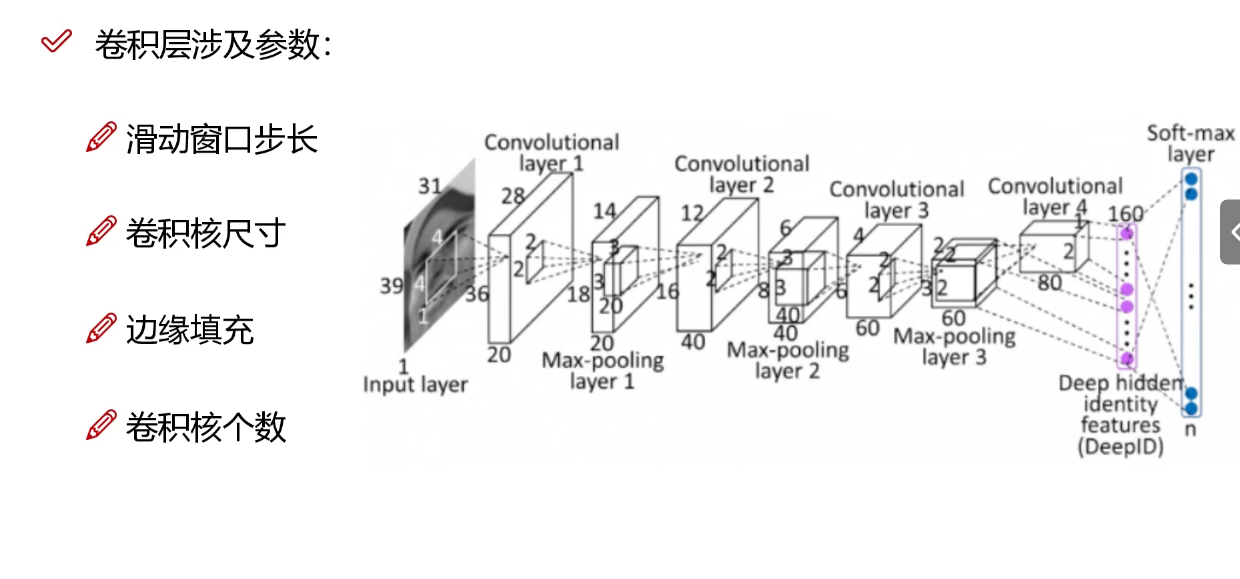
每一次卷积之后的特征图大小计算公式。


4.2.4. 池化层
池化层主要是为了压缩特征
可以对h和w进行压缩,c不能压缩。比如把h和w都缩小为之前的$\frac12$,那么整个体积就变成原来的$\frac14$。
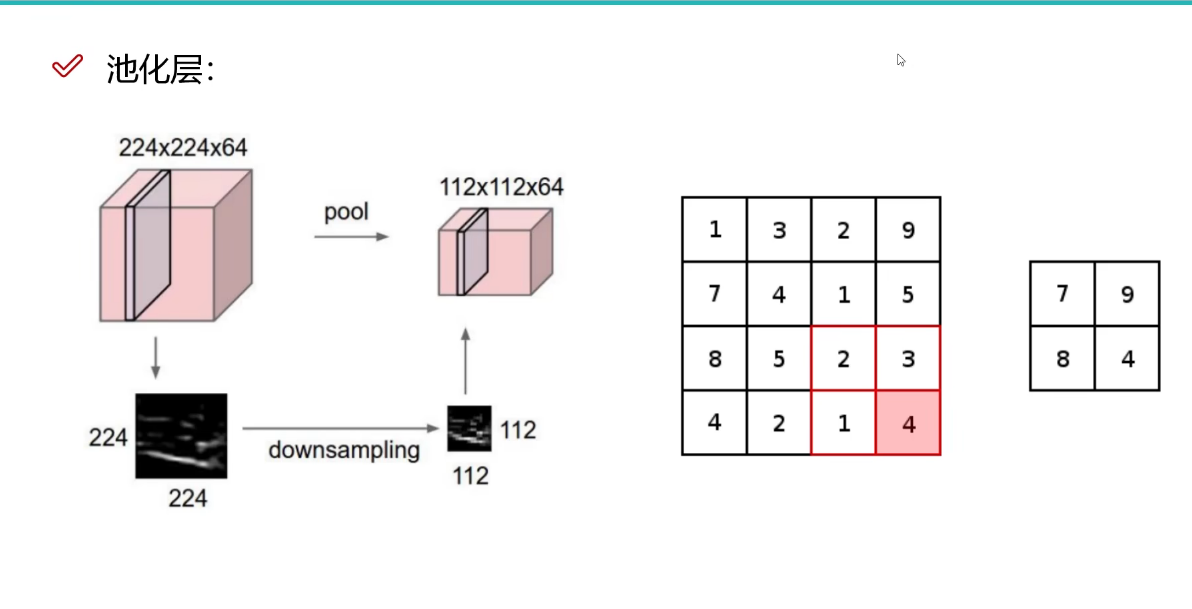
MAX POOLING
这是一种压缩算法,和卷积操作类似,把特征图分割成若干个小矩阵,取每个小矩阵里面的最大值作为代表特征,然后只取代表特征,以完成压缩,如下图所示:

整体流程
每一次卷积操作之后必须使用一个激活函数引入非线性因素,一个常见的CNN流程一般是两次卷积操作(每次之后跟ReLu函数),一次池化操作。然后经过多次这样的循环之后,最终需要一个全连接层把三维的一个东西展平成一维向量。
全连接层可看作一个传统的神经网络中的最后一层,因为我们最终要进行分类或者回归任务,最终得到的是一个一维的几个分类或者一组一维数据,而全连接层就是把一个$a\times{b}\times{c}$的三维矩阵展平成一个$abc\times1$的一维向量,具体来说就是把三维里面的每一个特征值取出来放到这个一维向量里。
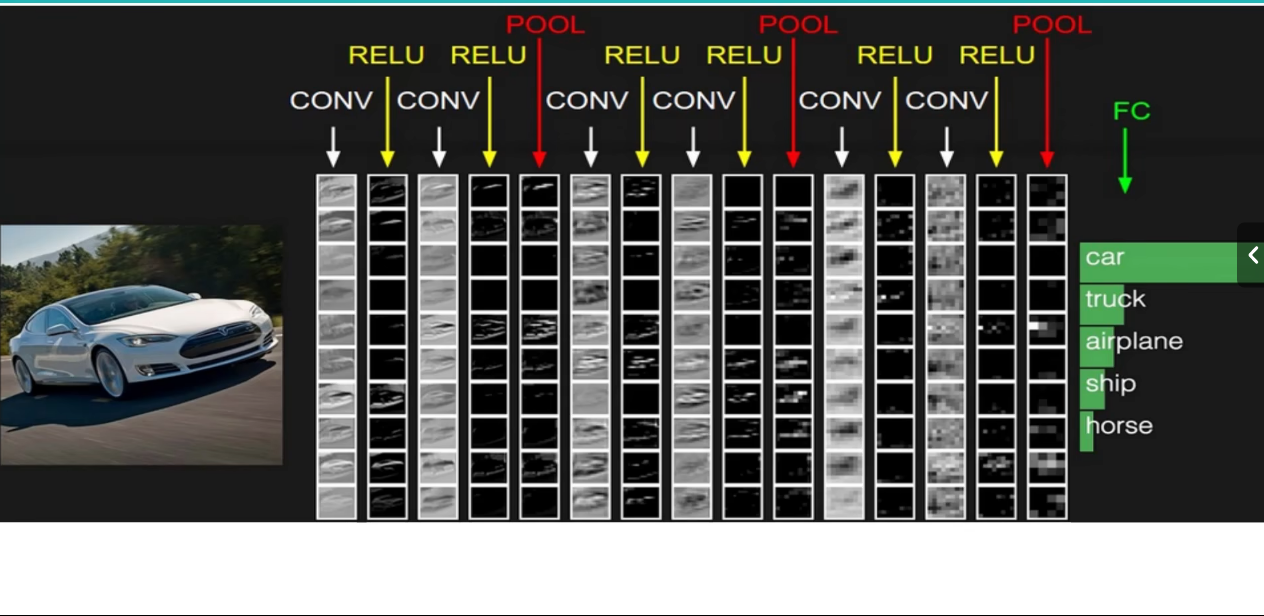
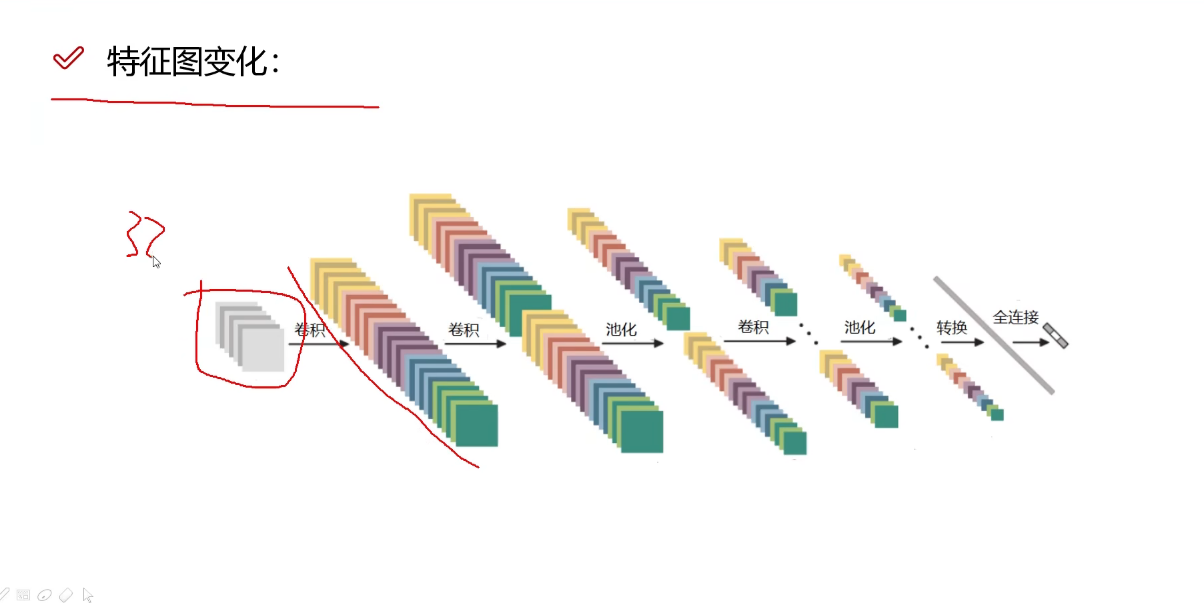
5. 编写模型
这个最基础的版本来自头歌机器学习 — 神经网络 (educoder.net)
根据之前给出的特征图的计算公式
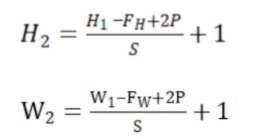
得到$H=W=\frac{28-5+2\times2}1+1=28$
构建卷积神经网络模型
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential( # 输入形状 (1, 28, 28)
nn.Conv2d(
in_channels=1, # 输入频道
out_channels=16, # 过滤器数量(卷积核)
kernel_size=5, # 过滤器大小
stride=1, # 过滤器移动/步长
padding=2, # 如果希望在conv2d后保持图像的宽度和长度不变,当步长为1时,padding=(kernel_size-1)/2
), # 输出形状 (16, 28, 28)
nn.ReLU(), # 激活函数
nn.MaxPool2d(kernel_size=2), # 在2x2区域内选择最大值,输出形状 (16, 14, 14)
)
self.conv2 = nn.Sequential( # 输入形状 (16, 14, 14)
nn.Conv2d(16, 32, 5, 1, 2), # 输出形状 (32, 14, 14)
nn.ReLU(), # 激活函数
nn.MaxPool2d(2), # 输出形状 (32, 7, 7)
)
self.out = nn.Linear(32 * 7 * 7, 10) # 全连接层,输出10个类别
# BP
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1) # 将conv2的输出展平为 (batch_size, 32 * 7 * 7)
output = self.out(x)
return output
整体代码
#encoding=utf8
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.utils.data as Data
import torchvision
import os
if os.path.exists('./step3/cnn.pkl'):
os.remove('./step3/cnn.pkl')
# 加载数据
train_data = torchvision.datasets.MNIST(
root='./step3/mnist/', # 数据集存放路径
train=True, # 这是训练数据
transform=torchvision.transforms.ToTensor(), # 将PIL.Image或numpy.ndarray转换为tensor
download=False, # 不下载数据
)
# 取6000个样本作为训练集
train_data_tiny = []
for i in range(6000):
train_data_tiny.append(train_data[i])
train_data = train_data_tiny
# mini_batch
train_loader = Data.DataLoader(dataset=train_data, batch_size=64, shuffle=True)
# 构建卷积神经网络模型
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential( # 输入形状 (1, 28, 28)
nn.Conv2d(
in_channels=1, # 输入频道
out_channels=16, # 过滤器数量(卷积核)
kernel_size=5, # 过滤器大小
stride=1, # 过滤器移动/步长
padding=2, # 如果希望在conv2d后保持图像的宽度和长度不变,当步长为1时,padding=(kernel_size-1)/2
), # 输出形状 (16, 28, 28)
nn.ReLU(), # 激活函数
nn.MaxPool2d(kernel_size=2), # 在2x2区域内选择最大值,输出形状 (16, 14, 14)
)
self.conv2 = nn.Sequential( # 输入形状 (16, 14, 14)
nn.Conv2d(16, 32, 5, 1, 2), # 输出形状 (32, 14, 14)
nn.ReLU(), # 激活函数
nn.MaxPool2d(2), # 输出形状 (32, 7, 7)
)
self.out = nn.Linear(32 * 7 * 7, 10) # 全连接层,输出10个类别
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1) # 将conv2的输出展平为 (batch_size, 32 * 7 * 7)
output = self.out(x)
return output
cnn = CNN()
# SGD表示使用随机梯度下降方法,lr为学习率
optimizer = torch.optim.SGD(cnn.parameters(), lr = 0.1)
# 交叉熵损失函数
loss_func = nn.CrossEntropyLoss()
for step, (x, y) in enumerate(train_loader):
b_x = Variable(x) # batch x
b_y = Variable(y) # batch y
output = cnn(b_x) # cnn输出
loss = loss_func(output, b_y) # 计算损失
optimizer.zero_grad() # 清空上一步的残余更新参数值
loss.backward() # 误差反向传播,计算参数更新值
optimizer.step() # 将参数更新值施加到net的parameters上
# 保存模型
torch.save(cnn.state_dict(), './step3/cnn.pkl')
6. 优化
6.1. 优化的意义
在kaggle这个网站中,在手写数字识别这个比赛中,已经有很多人做到了1的正确率,这是了不起的,这也是我们初学者所努力的方向。只有在对模型不断地调参,不断地优化地过程中,我们才能深切地感受到神经网络乃至机器学习的魅力。

import torch
import torchvision
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
# torch.backends.cudnn.enabled = False
# 优先使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 打印使用的设备
print(device)
# 一些超参数
# 定义训练过程中的 "epoch" 数量。一个 epoch 指的是整个训练集被遍历一次。
n_epochs = 3
# 定义训练过程中的批次大小。批次大小是指在更新模型参数之前要处理的数据样本数量。
batch_size_train = 64
# 定义测试过程中的批次大小。在评估模型性能时,会一次处理这么多的数据样本。
batch_size_test = 1000
# 定义优化器的学习率。学习率是一个控制模型参数更新步长的参数。
learning_rate = 0.01
# 定义优化器的动量。动量是一种帮助优化器在优化过程中保持方向并加速收敛的技术。
momentum = 0.5
# 定义训练过程中的日志记录间隔。每处理这么多个批次,就会打印一次训练日志。
log_interval = 10
# 设置随机数生成器的种子。设置随机种子可以确保实验的可重复性。
random_seed = 1
torch.manual_seed(random_seed)
# 创建训练数据加载器
train_loader = torch.utils.data.DataLoader(
# 加载 MNIST 数据集,如果数据集不存在,则下载数据集
torchvision.datasets.MNIST('./data/', train=True, download=True,
# 对数据进行预处理,包括将数据转换为张量,并进行标准化
transform=torchvision.transforms.Compose([
# 将图像数据转换为 PyTorch 张量
torchvision.transforms.ToTensor(),
# 对数据进行标准化,参数是 MNIST 数据的均值和标准差
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
# 设置批次大小
batch_size=batch_size_train,
# 在每个 epoch 开始时,洗牌数据
shuffle=True)
# 创建测试数据加载器
test_loader = torch.utils.data.DataLoader(
# 加载 MNIST 数据集,如果数据集不存在,则下载数据集
torchvision.datasets.MNIST('./data/', train=False, download=True,
# 对数据进行预处理,包括将数据转换为张量,并进行标准化
transform=torchvision.transforms.Compose([
# 将图像数据转换为 PyTorch 张量
torchvision.transforms.ToTensor(),
# 对数据进行标准化,参数是 MNIST 数据的均值和标准差
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
# 设置批次大小
batch_size=batch_size_test,
# 在每个 epoch 开始时,洗牌数据
shuffle=True)
# 使用 enumerate 函数对测试数据加载器进行迭代,返回一个枚举对象
examples = enumerate(test_loader)
# 使用 next 函数获取枚举对象的下一项,即一个批次的数据和对应的目标
batch_idx, (example_data, example_targets) = next(examples)
# 将数据和目标移动到指定的设备上(CPU 或 GPU)
example_data, example_targets = example_data.to(device), example_targets.to(device)
# 创建一个新的图形窗口
fig = plt.figure()
# 开始一个循环,循环6次。在每次循环中,都会创建一个子图并显示一张图像和对应的标签
for i in range(6):
# 创建一个子图。2, 3, i + 1 表示创建一个2行3列的子图网格,并在第 i + 1 个位置创建子图
plt.subplot(2, 3, i + 1)
# 调整子图的布局,使得子图之间的间距适当,避免重叠
plt.tight_layout()
# 显示一张图像。example_data[i][0].cpu() 是要显示的图像,它被转移到 CPU 以便于绘图。cmap='gray' 表示使用灰度色图。interpolation='none' 表示不使用插值
plt.imshow(example_data[i][0].cpu(), cmap='gray', interpolation='none') # Move to CPU for plotting
# 设置子图的标题。标题是 "Ground Truth: " 后面跟着对应的标签
plt.title("Ground Truth: {}".format(example_targets[i]))
# 隐藏子图的 x 轴和 y 轴的刻度
plt.xticks([])
plt.yticks([])
# 显示图形窗口。在 Python 脚本中,需要调用 plt.show() 来显示图形。在 Jupyter notebook 中,通常不需要调用 plt.show(),因为图形会自动显示
plt.show()
# 定义一个名为 Net 的神经网络类,继承自 nn.Module
class Net(nn.Module):
# 初始化函数
def __init__(self):
# 调用父类 nn.Module 的初始化函数
super(Net, self).__init__()
# 定义第一个卷积层,输入通道数为1,输出通道数为10,卷积核大小为5
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
# 定义第二个卷积层,输入通道数为10,输出通道数为20,卷积核大小为5
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
# 定义一个 dropout 层,用于防止过拟合
self.conv2_drop = nn.Dropout2d()
# 定义第一个全连接层,输入节点数为320,输出节点数为50
self.fc1 = nn.Linear(320, 50)
# 定义第二个全连接层,输入节点数为50,输出节点数为10
self.fc2 = nn.Linear(50, 10)
# 定义前向传播函数
def forward(self, x):
# 对输入 x 应用第一个卷积层,然后应用最大池化层(池化窗口大小为2),然后应用 ReLU 激活函数
x = F.relu(F.max_pool2d(self.conv1(x), 2))
# 对 x 应用第二个卷积层,然后应用 dropout 层,然后应用最大池化层(池化窗口大小为2),然后应用 ReLU 激活函数
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
# 将 x 的形状变为(-1, 320),-1 表示自动计算该维度的大小
x = x.view(-1, 320)
# 对 x 应用第一个全连接层,然后应用 ReLU 激活函数
x = F.relu(self.fc1(x))
# 对 x 应用 dropout,dropout 的比例由 self.training 决定
x = F.dropout(x, training=self.training)
# 对 x 应用第二个全连接层
x = self.fc2(x)
# 对 x 应用 log_softmax,计算每个类别的对数概率
return F.log_softmax(x, dim=1)
# 创建一个网络实例,并将其移动到指定的设备上(例如 GPU 或 CPU)
network = Net().to(device)
# 创建一个随机梯度下降优化器,用于更新网络的参数
# network.parameters() 是网络的所有可训练参数
# lr 是学习率,控制参数更新的步长
# momentum 是动量,可以加速 SGD 在相关方向上的收敛,并抑制震荡
optimizer = optim.SGD(network.parameters(), lr=learning_rate, momentum=momentum)
# 创建列表以存储训练和测试过程中的损失
train_losses = []
train_counter = []
test_losses = []
# 创建一个计数器,用于记录每个测试周期结束时处理的总样本数
test_counter = [i * len(train_loader.dataset) for i in range(n_epochs + 1)]
# 定义训练函数
def train(epoch):
# 将网络切换到训练模式
network.train()
# 遍历训练数据加载器中的所有批次
for batch_idx, (data, target) in enumerate(train_loader):
# 将数据和目标移动到指定的设备上
data, target = data.to(device), target.to(device)
# 在进行新的一次前向传播之前,先将优化器中的梯度清零
optimizer.zero_grad()
# 通过网络进行前向传播,计算出预测值
output = network(data)
# 计算损失,这里使用的是负对数似然损失
loss = F.nll_loss(output, target)
# 通过损失进行反向传播,计算出梯度
loss.backward()
# 使用优化器更新网络的参数
optimizer.step()
# 每隔一定数量的批次,打印训练状态并保存损失
if batch_idx % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data),
len(train_loader.dataset),
100. * batch_idx / len(train_loader),
loss.item()))
# 将损失添加到损失列表中
train_losses.append(loss.item())
# 记录处理过的样本数量
train_counter.append((batch_idx * 64) + ((epoch - 1) * len(train_loader.dataset)))
# 保存网络的状态字典和优化器的状态字典
torch.save(network.state_dict(), './model.pth')
torch.save(optimizer.state_dict(), './optimizer.pth')
# 定义测试函数
def test():
# 将网络切换到评估模式,这会关闭某些特定于训练的行为,如 Dropout
network.eval()
# 初始化测试损失和正确预测的数量
test_loss = 0
correct = 0
# 使用 torch.no_grad() 上下文管理器,关闭自动求导,减少内存使用并加速计算
with torch.no_grad():
# 遍历测试数据加载器中的所有批次
for data, target in test_loader:
# 将数据和目标移动到指定的设备上
data, target = data.to(device), target.to(device)
# 通过网络进行前向传播,计算出预测值
output = network(data)
# 计算并累加损失,这里使用的是负对数似然损失
# reduction='sum' 表示将所有批次的损失求和,而不是平均
test_loss += F.nll_loss(output, target, reduction='sum').item()
# 获取预测的类别(即概率最大的类别)
pred = output.data.max(1, keepdim=True)[1]
# 计算并累加正确预测的数量
correct += pred.eq(target.data.view_as(pred)).sum()
# 计算平均损失
test_loss /= len(test_loader.dataset)
# 将平均损失添加到损失列表中
test_losses.append(test_loss)
# 打印测试集的平均损失和准确率
print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
# 开始训练神经网络的第一个周期
train(1)
# 在训练一个周期后,使用测试集评估模型的性能
test()
# 对于给定的周期数,进行以下操作
for epoch in range(1, n_epochs + 1):
# 训练模型。这里的 epoch 是当前的周期编号
train(epoch)
# 在每个周期结束后,使用测试集评估模型的性能
test()
# 创建一个新的图形
fig = plt.figure()
# 绘制训练损失。train_counter 是 x 轴(训练样本数量),train_losses 是 y 轴(训练损失),颜色设置为蓝色
plt.plot(train_counter, train_losses, color='blue')
# 绘制测试损失。test_counter 是 x 轴(训练样本数量),test_losses 是 y 轴(测试损失),颜色设置为红色。这里使用散点图表示
plt.scatter(test_counter, test_losses, color='red')
# 添加图例,'Train Loss' 对应蓝色的训练损失线,'Test Loss' 对应红色的测试损失点,位置在右上角
plt.legend(['Train Loss', 'Test Loss'], loc='upper right')
# 设置 x 轴的标签为 'number of training examples seen'
plt.xlabel('number of training examples seen')
# 设置 y 轴的标签为 'negative log likelihood loss'
plt.ylabel('negative log likelihood loss')
# 从测试数据加载器中获取一个迭代器
examples = enumerate(test_loader)
# 使用 next 函数从迭代器中获取下一个元素,这将返回一个批次的索引和数据(包括数据和目标)
batch_idx, (example_data, example_targets) = next(examples)
# 将数据和目标移动到设备(例如 GPU)上
example_data, example_targets = example_data.to(device), example_targets.to(device)
# 不计算梯度,因为这是推理阶段,不需要反向传播
with torch.no_grad():
# 使用网络对数据进行预测
output = network(example_data)
# 创建一个新的图形
fig = plt.figure()
# 对于前 6 个样本
for i in range(6):
# 在 2x3 的子图中创建一个新的子图
plt.subplot(2, 3, i + 1)
# 自动调整子图参数以给定指定的填充
plt.tight_layout()
# 绘制样本的图像,颜色映射为灰度
plt.imshow(example_data[i][0].cpu(), cmap='gray', interpolation='none')
# 添加标题,显示预测的类别
plt.title("Prediction: {}".format(output.data.max(1, keepdim=True)[1][i].item()))
# 删除 x 轴的刻度
plt.xticks([])
# 删除 y 轴的刻度
plt.yticks([])
# 显示图形
plt.show()
# 创建一个新的网络实例并移动到设备上
continued_network = Net().to(device)
# 创建一个新的优化器实例,使用网络的参数
continued_optimizer = optim.SGD(network.parameters(), lr=learning_rate, momentum=momentum)
# 从文件中加载网络的状态字典
network_state_dict = torch.load('model.pth')
# 使用状态字典更新网络的参数
continued_network.load_state_dict(network_state_dict)
# 从文件中加载优化器的状态字典
optimizer_state_dict = torch.load('optimizer.pth')
# 使用状态字典更新优化器的参数
continued_optimizer.load_state_dict(optimizer_state_dict)
# 对于给定的周期数
for i in range(4, 9):
# 更新测试计数器
test_counter.append(i * len(train_loader.dataset))
# 训练网络
train(i)
# 测试网络
test()
# 创建一个新的图形
fig = plt.figure()
# 绘制训练损失
plt.plot(train_counter, train_losses, color='blue')
# 绘制测试损失
plt.scatter(test_counter, test_losses, color='red')
# 添加图例
plt.legend(['Train Loss', 'Test Loss'], loc='upper right')
# 设置 x 轴的标签
plt.xlabel('number of training examples seen')
# 设置 y 轴的标签
plt.ylabel('negative log likelihood loss')
# 显示图形
plt.show()
7. 总结
作为CNN入门教程,本文会持续更新。